Decoupled Sector Caches: Conciliating Low Tag Implementation Cost and Low Miss Ratio
- Hide Paper Summary
Link: https://ieeexplore.ieee.org/document/288133/
Year: ISCA 1994
Keyword: Sector Cache
This paper proposes decoupled sector cache. Sector cache has been proposed long before this paper as a way of reducing tag storage. Conventional caches statically bind one data slot to one tag slot, such that when the tag is assigned an address, the corresponding data block is always fetched from the lower level. Such organization dedicates non-negligible storage to store address tags, which does not contribute to processor performance (note that this paper was published in 1994, at which time transistors are not as dense as it is today). This is especially true for caches with shorter lines. For example, if the cache line size is 16 bytes as in MIPS R4000 architecture, the 24 bit tag cost can be as large as 18.75%. The paper also points out that increasing cache line size can effectively improve the utilization of on-chip SRAM storage. This, however, has negative effect such as increased bandwidth usage per transaction and possibilities of false sharing in the case of coherence.
Sector caches use larger-than-usual block size without introducing excessive data transfer and coherence invalidation by allowing a large cache line to be further divided into smaller units, called “sectors”. Sectors are the basic unit of data transfer and coherence just like a regular cache line. The address tag of the sector, however, is only implied by the tag of the entire block and its index within the block. Given a sector size s, index i, and tag address t, the implied address of the sector is t + s * i, i.e. all sectors in a cache block are linearly mapped to the underlying address space. Coherence and valid bits are still stored on a per-sector basis to support individual line fetch and invalidation. In this paper the term “sector” is used to indicate the basic unit of data transfer, and term “line” or “block” are used to indicate all sectors under the same tag.
Although sector caches reduce the number of tags for the same number of sectors, it inevitably decreases cache hits for some workloads, since sector cache assumes higher locality for applications. A sector cache with S sectors (per line), T tags can at most map at most T blocks of size (s * S) each, while a regular cache with B blocks (and B tags) can map at most B blocks of size b each. If these two caches are of equal sizes, then B = T * S, which implies that as long as the workload accesses K distinc locations on the address space where T < K < B, regular caches can always perform better than a sector cache due to less misses. This observation is also confirmed in the paper with real world workloads.
The issue with sector caches is that a single tag maps a relative large area in the address space. If an access falls out of the mapped range of the tag, it will be a miss to the tag, regardless of how large the mapped area is. One of the most straightforward additions is to allow several tags share a data block. Instead of always map a linear region on the address space, we now allow mapping several non-overlapping regions within the same block. The difference between a decoupled sector cache and a regular sector cache is that these mapped regions may “interleave” with each other, i.e. blocks on different offsets may be using different base address tags.
To help finding which sectors in the block belong to which tags, each sector now is equipped with two extra fields. The first is the normal “valid” field indicating whether the sector is mapped by any of the tag. This field used to be stored for each sector together with the address tag in a normal sector cache. In the proposed design, however, they are now stored in a per-sector manner, since now there are multiple tags, and having each of them saving a separate “valid” bit vector causes unnecessary redundancy. If the valid field is off for sector on offset i, the sector is not mapped by any of the tag. If the valid field is on, then the sector is mapped, but the base address is still unknown. The second per-sector field identifies the tag that maps the sector. Given that P tags can share a cache block, this field consists of log2(P) (rounded up) bits, which stores the identity of the tag mapping the address. On a cache lookup, both fields are checked. The cache controller signals a hit, if and only if the sector on the offset has “valid” bit on, and the address tag indicated by the second field matches the requested address. Note that in the meantime the tag lookup is still performed, and the tag is located by comparing the address with corresponding bits in the requested address. We compare the identity of the tag and the ID stored in the second field, and signal a hit if these two matches.
The tag lookup algorithm is slightly modified to fit into this model while the set lookup is unchanged from a regular cache. Given X sets and a Y way set-associative sector cache with P tags and S sectors per line, we extract the lowest log2(X) bits after the sector offset to address the tag, and use the rest of the high-order bits minus the lowest log2(P) bits as the address tag to be stored in the tag array (also used for comparison). The log2(P) bits between the set index and address tag are then used to address tags within the set. Note that now each set contains (Y * P) tags, and each element contains P tags. We use the middle log2(P) bits to address one tag from each set element, and compare the rest of the high bits to determine if there is a hit. This is slightly more complicated than a non-sector cache, where there is only Y tags per set, and 1 tag per set element. No bit between the set index and address tag is dedicated to retrieving a tag from decoupled P tags. After the tag is retrieved, in case there is an address match, we also check the sector’s tag ID field. If these two match, indicating that the sector stored on the offset (addressed using log2(S) bits before the set index) indeed belongs to the tag, a hit is signaled. Otherwise a miss is signaled.
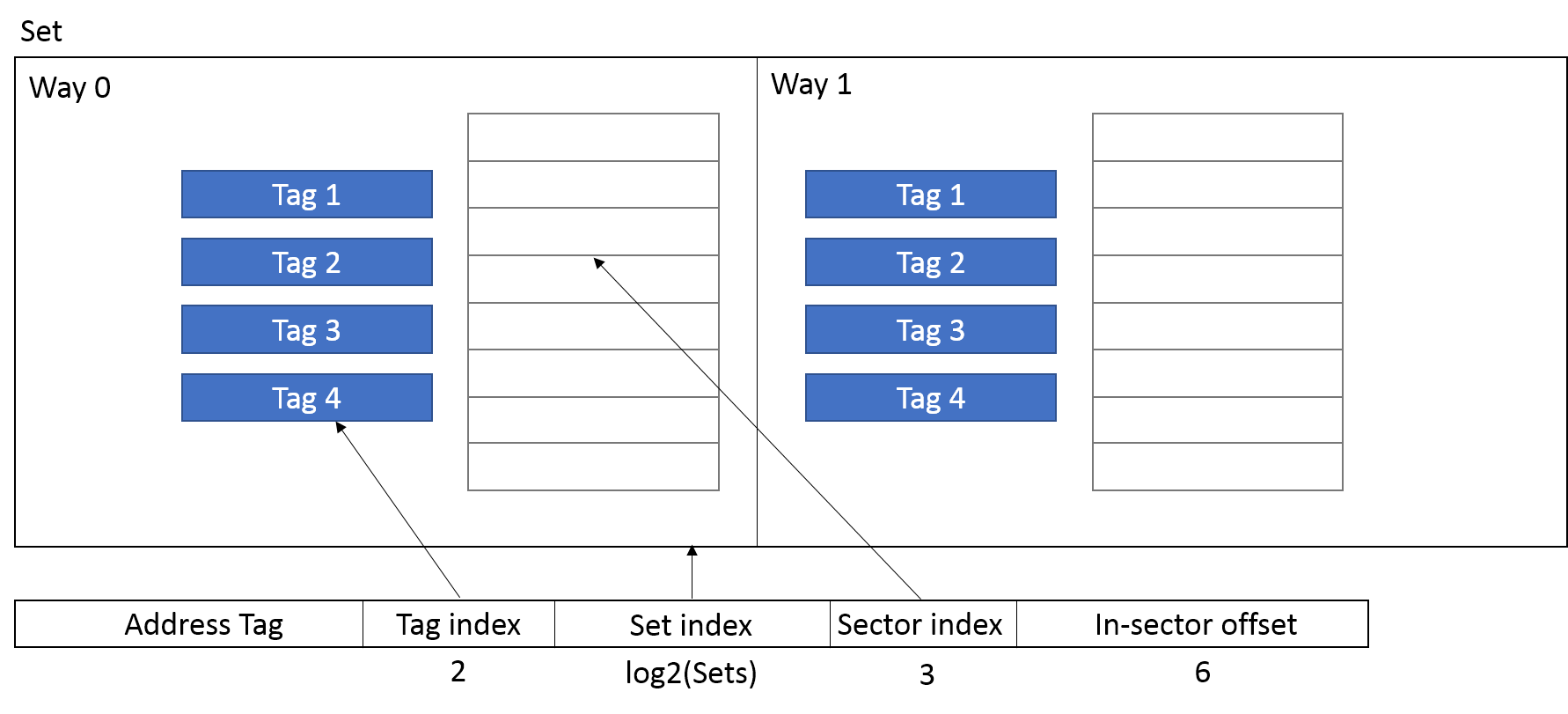
Our previous discussion assumes direct-mapped tag array and sector, which is indexed by a few middle bits from the requested address. The paper also suggests that the organization of tag arrays and sectors can also be set-associative themselves, independent of the overall organnization of the cache. After locating the set using a log2(X) bit set index, the cache controller should further locate the tags and sectors for address comparison. For a set-associative tags consisting of x sets and y ways, where (x * y) = P, we first take the low log2(x) bits from the address as the set index, and then read out all tags within the set. If any one of the address tag matchs the bits after the tag set index, a tag hit is signaled. In the meantime, the sector is also located using a similar process. For a sector array consisting of x’ sets and y’ ways, where (x’ * y’) = S, we use log2(x’) bits from the address to first determine the sector set. Then all y’ ways are read out, and the one whose tag ID field matches the tag that gets hit is the data sector that gets hit. If both a tag hit and sector hit are signaled, a cache hit is signaled. In all other cases, cache miss occurs, and replacement will be made. As pointed out by the paper, the tag array and sector array need not be of the same organization. They are merely a way of determining which subset of tags or sets could an address be stored. Higher associativity means an address could be found in more potential locations, enabling more flexible caching policy, at the cost of more read operations and more complex comparison hardware when the set is accessed (all ways are read).
Two types of misses can occur with a decoupled sector cache. The first type is when the tag hits, but no sector can be found for that tag. This is a minor miss, since we only need to evict an existing sector from the current set, without invalidating any tag. An eviction policy should be defined for sector sets to handle minor misses, if sectors are set-associative. A major miss happens when none of the tags match the requested address. In this case, one tag from the current set should be evicted. In addition, all sectors with the tag ID matching the evicted tag should also be evicted. This is a rather complicated process that can increase cache miss handling latency, but the paper claims that it can be partially or fully overlapped with data fetching.